
Оглавление:






Предсказание
- Прогноз 1 Предположим, вы оцениваете модель ;;, = a + u + u, (10.69) Период наблюдения (t = 1, …, T): y = a + bxr (10,70) Если есть значение переменной x после выборки (например, xm + p), Вы можете предсказать соответствующее значение у. Pm + P = * + bxm + p (10,71) Такие прогнозы могут быть важны по двум причинам. Ты первый Вы можете быть одним из эконометристов, чья работа заключается в изучении экономики Будущее мира.
- Некоторые эконометрики изучают экономическое право. Для других это просто средство для достижения более практической цели, прежде чем Посмотри что получится. Макроэкономические прогнозы во многих странах Reach имеет высокую репутацию и эконометрическую команду Министерство финансов или другие правительственные учреждения живут Частные финансовые институты, университеты, исследователи.
Меры по улучшению понимания того, как работает экономика. Людмила Фирмаль
Учреждение, и его прогнозы активно используются Интерпретация и интерпретация государственной политики или деловых целей. Когда хочешь Другие прогнозы публикуются в СМИ и, как правило, многие прогнозы Больше внимания, чем большинство других видов экономического анализа, В основном его природа и в отличие от большинства других, 1 Используйте термины «прогноз» и «прогноз» для перевода в соответствии с термином Авторская нанология.
Он объяснит немного подробнее. (Ред.) 309 Типы экономического анализа, которые могут быть легко поняты широкой публикой Ninomu. Даже люди с совершенно нематематическими и нетехническими личностями Дом ума может понять значение оценки будущего уровня Безработица, инфляция и др. Однако есть еще одно приложение для эконометрического прогнозирования.
Независимо от проблем большинства эконометристов, Вы заняты своими прогнозами? Обеспечить устойчивые методы оценки. Регрессионная модель Правительство, чем диагностическая статистика используется до сих пор. Прежде чем продолжить, вам нужно уточнить, что вы понимаете По прогнозу. К сожалению, в литературе по эконометрике этот термин В зависимости от вашего понимания xm +, он может иметь несколько различных значений В формуле (10.71).
Различают прогноз и прогноз. Этот раздел Заявления создаются в соответствии с обычной терминологией (например: E. Harvey (Harvey, 1981)), но здесь используется терминология Не очень стандартно. прогнозирование Если вам известно значение xm + p, опишите ym + p как прогноз. Как ты Это может быть? В общем, эконометрика хочет включить все доступные данные.
Максимизируйте размер выборки и минимизируйте в результате Дисперсия оценки. Следовательно, xm — последнее записанное значение. JC во время оценки регрессии. Однако есть две возможные ситуации: Когда xm + p уже известен: при ожидании периода, превышающего p, после оценки reg россии и ранее ограничивал период выборки, Некоторые недавние наблюдения были сделаны.
Как вы увидите в следующем разделе, Важная причина для этого может быть без задержки Точность прогнозирования потока модели. Так, например, снова обратитесь к общему уравнению модели связи (3.34). Инфляция и инфляция заработной платы, все время Да, я выбрал и оценил уравнение р = 1,0 + 0,8 *, (10,72) Где p и w — годовые уровни общей инфляции и инфляции заработной платы.
Проценты, каждый знает это в одном пост-выборе Уровень инфляции заработной платы составлял 6% в год. Тогда вы можете утверждать Прогноз по общей инфляции составляет 5,8%. Конечно мы должны быть сразу сопоставимы с фактическим уровнем инф Рассчитать инфляцию и прогноз ошибки на этот год. Это равно разнице Между прогнозируемым значением и фактическим значением.
В общем, для рг + л, — Прогнозируемое значение, ut + p-действительное число, ошибка прогноза fT + определяется как Почему я получаю ошибку прогноза? Для этого есть две причины. Us. Сначала значение ym + p было вычислено с использованием оценки параметров 310 Ров а и б вместо фактических значений. Во-вторых, t + p не считается Случайный член ит + р. Целая часть m + p.
В будущем Предположим, что данные содержат наблюдения изменений (T + t) пу. Первое наблюдаемое значение T (период выборки) используется для пост Рой-регресс и последний м (период или интервал прогнозирования) Изменения для анализа точности прогноза. случай Предположим, вы оценили функцию спроса на продукты питания.
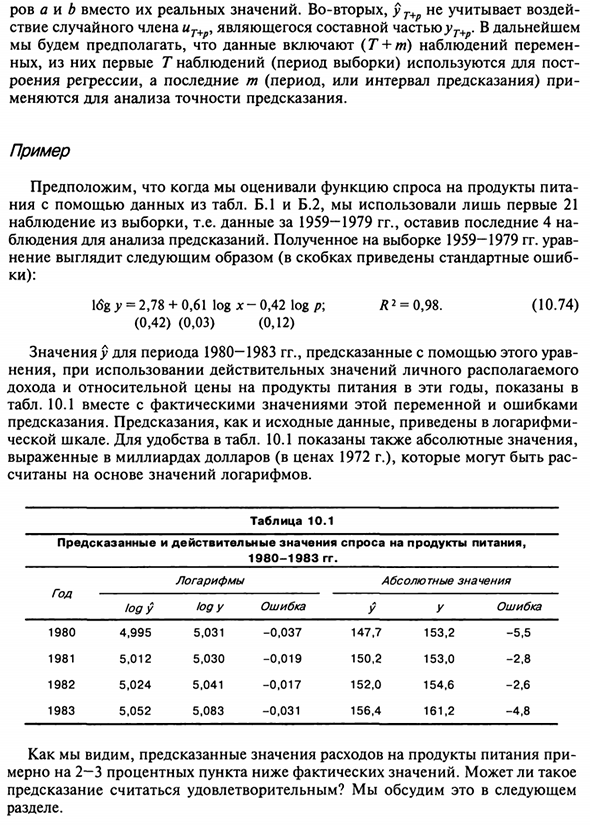
- Используйте данные в таблице. B.1 и B.2, использовались только первые 21 Наблюдения из выборки, т.е. данные за 1959-1979 гг. Последние четыре Наблюдения для прогнозного анализа. Получено по образцам 1959-1979 гг. Дополнительная логи Мнения таковы (в скобках указаны стандартные ошибки) ки): I6G у = 2,78 + 0,61 log x-0,42 log p, R2 = 0,98. (10.74) (0,42) (0,03) (0,12)
Прогнозируемое значение y между 1980 и 1983 годами, предсказанное с использованием этой формулы Использование личной одноразовой реальной стоимости Доход этих лет и относительные цены на продукты питания Tab. 10.1 Эта переменная и фактическое значение ошибки Прогнозирование.
Как и исходные данные, прогноз дается логарифмически Масштаб. Людмила Фирмаль
Для удобства в таблице. 10.1 также отображает абсолютные значения. В миллиардах долларов (по цене 1972 года) Чтение на основе логарифмического значения. предсказанный год 1980 1981 1982 1983 Логи 4995 5,01 2 5024 5052 Таблица 10.1 Фактическая стоимость спроса 1980-198 3 года. логарифм Логи 5031 5030 5041 5083 ошибка -0,037 -0,01 9 -0,01 7 -0,031 Для еды Абсолютное значение в 147,7 150,2 152,0 156,4 в 153,2 153,0 154,6 161,2 ошибка -5,5 -2, 8 -2, 6 -4,8
Как видите, прогнозируемая стоимость потребления продуктов питания Около 2-3 процентов ниже, чем фактическое значение. Вы можете сделать Являются ли прогнозы удовлетворительными? Это будет объяснено в следующем Раздел прогноза Если вы хотите предсказать конкретное значение ut + p, не зная действительного числа значение х T + P, сказал сделать прогноз (по крайней мере, Используйте терминологию в этом тексте).
Макроэкономическое предвидение, В этом смысле это обычно прогноз, который публикуется в прессе. Politi Ков, особенно широкая публика, мало интересуется «двусторонней» экологией Логика «С другой стороны … но если нет, С другой стороны, обычно у каждого есть точная и четкая оценка, дополнительная В то же время это может быть границей для возможных ошибок, но во многих случаях даже без нее Go.
Прогноз менее точен, чем прогноз Действие дополнительного источника ошибки-предсказания значения xm + p. Очевидно, прогнозирующие эконометрики, как правило, Минимизируйте эту дополнительную ошибку, моделируя максимально точно Поведение переменной х.
Иногда другая модель для нее, иногда Подгоните уравнение y и уравнение x к одной модели и Одновременная оценка других серий отношений и так называемой системы Уравнение (объяснено в главе 11). Свойства прогноза, полученные с использованием OLS Следующее обсуждение будет в основном сосредоточено на прогнозировании.
Рассмотрим характеристики коэффициента рег, а не прогноз Случайный срок ответа и свойства, а не переменная х для этого значения Оценка неизвестна. И это имеет хороший смысл. значение ut + p Генерируется в том же процессе, что и выборочное значение переменной y [затем ит + р следует формуле (10.69), которая удовлетворяет условию Ха усса — марков].
Ппри построении прогноза ут + с использованием уравнений (10.71), среднее значение ошибки предсказания fT + становится равным нулю, Минимальная дисперсия. Первое свойство очень легко продемонстрировать. = E (a + bxT + p) -E (a + $ xT + p + uT + p) = = E (a) + xT + pE (b) -a-Pxr + /, -E (uT + p) = = a + pxr + y, -cx-pxr + /, = 0, (10,75) Поскольку E (a) = a, E (b) = (5 и E (uT + p) = 0, характеристики не доказаны.
Минимальная разница (свидетельство Джон Джонстон [Джонстон, 1984] или J. Thomas (Thomas, 1983)). Оба эти свойства сохраняются Общий случай множественного регрессионного анализа. Для парных уравнений регрессии определяется выборочная дисперсия / ^. как (./ „Z \ l \ (/ v Z \ 2 \ pop.var (/ r + / l) = 1 + -1 + (xm + px) n X (*, — *): \ Op = 1 + -n1 /? Var (x + (xm + p-) x) | a «> (10,76) 31 2 Где x и Var (x) — выборочное среднее значение и дисперсия переменной x.
Формула выглядит следующим образом, и неудивительно, что чем больше значение x отклоняется От среднего значения выборки дисперсия ошибки предсказания увеличивается. от Формула продолжается, но неудивительно, что объем большой Если дисперсия ошибки выборки и прогнозирования низкая, а нижний предел низкий, Поскольку размеры выборки, равные ol, увеличиваются, оценки a и b стремятся быть верными.
Соответствующее значение коэффициента (при выполнении условия Гаусса са — марков) и единственная причина ошибок прогнозирования С чаем t + p, с любой дисперсией по определению. Прогноз доверительный интервал Вы можете получить стандартное значение ошибки прогнозирования, если: Вычислите nol по уравнению $ * (10.76) и извлеките квадратный корень.
Тогда отн Отношение значения (yT + p-yt + p) к стандартной ошибке оценки Соответствует периоду выборки Общее количество степеней свободы. Отсюда вы можете обрести уверенность Фактическое значение ut + p вала: 9 т + р-крит х с. О программе. <ym + p <pm + p + tKpum x s. О (10.77) Где t m является критическим значением t при данном уровне значимости и числе О свободе и о. -Стандартная ошибка прогнозирования.
Рисунок 10.5 Поворот Общий вид показывает отношения с доверием Интервал продвижения Легенда и пояснительные значения переменных. Т * П Верхний предел Доверительный интервал доверие интервал + BX К началу страницы Нижний предел Доверительный интервал Рисунок 10.5. Прогноз доверительный интервал В уравнении множественной регрессии уравнение, соответствующее (10.76)
Это более сложная форма, и ее можно лучше представить, используя оборудование матричной алгебры. Тем не менее, есть простой трюк Может использоваться для расчета стандартного значения ошибки с помощью Компьютер. Оценить уравнение регрессии с комбинацией образцов Добавить (различные) фиктивные изменения в выборку и прогнозные периоды Нью-Йорк для каждого наблюдения в прогнозном периоде.
Это Включить в модель с набором фиктивных переменных DT + l, DT + 2, …, Dr + m D T + p = 0 для всех наблюдений, кроме наблюдения T + p Но один. Оцените не литературные коэффициенты, как показано Переменная и ее стандартное отклонение Уравнение регрессии рассчитано только для периода выборки (см. D. Salkever [Salkever, 1976] и J.-M. Dufour [Dufour, 1980]).
Компьютер Используйте фиктивные переменные, чтобы получить точное значение каждого Наблюдать и делать это в течение прогнозного периода, Фиктивная переменная к значению определенной ошибки прогноза Сплит выше. Стандартная ошибка этого коэффициента равна стандартной ошибке Предсказание Ke. случай Стандартная ошибка прогноза в уравнении функции спроса на продукцию Еда в 1980 году 0,019.
Если число степеней свободы равно 18, и Уровень значимости 5% // Статистический критический уровень составляет 2.10. Вы можете получить следующий 95% доверительный интервал Легенда года: 4,995-2,10 х 0,019 <логи <4,995 + 2,10 х 0,019 (10,78) Это 4955 <ology <5035. (10.79) Как видите, фактическое значение переменной попадает в это доверие Поскольку это интервал, по крайней мере, прогноз этого года Можно считать удовлетворительным. Это верно для оставшихся лет периода.
Прогнозирование. движение 10,13. Рассчитать прогнозы и их прогнозы, используя косвенный метод Salkever Стандартная ошибка выбранной логарифмической функции спроса Товарные. Добавьте фиктивные переменные в последние четыре случая, Рассчитать погрешность прогноза на эти годы по формуле Ressii получены из первых 21 наблюдений. Добавьте это к реальному значку. Получите прогноз. Рассчитать профессиональные доверительные интервалы Гнозис как минимум год назад.
Смотрите также:
| Гипотеза Фридмена о постоянном доходе | Тесты на устойчивость |
| Рациональные ожидания | Метод Бокса—Дженкинса и анализ временных рядов |
Если вам потребуется помощь по эконометрике вы всегда можете написать мне в whatsapp.
